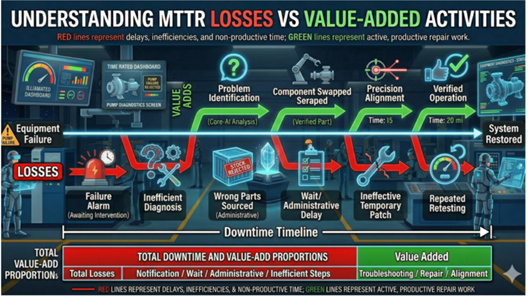
Mean Time to Repair (MTTR) is a common key performance indicator used to check how reliable a plant is. Usually, MTTR is just seen as the time taken from when a failure happens to when the equipment is fixed. But this simple calculation does not show the real challenges. Many important steps like identifying the problem, understanding the root cause, planning the repair, and checking after the repair are often missed. In plants, where safety, rules, and working conditions matter a lot, lowering MTTR is not only about fixing things faster. It means removing delays in making decisions at every step from when an incident occurs to the equipment is back to normal steady state operating conditions. This article explains MTTR in detail, shows practical ways to improve it using digital tools, and gives clear ideas for O&M leaders, engineers, and managers to make things better.
MTTR Decomposition: The end-to-end Incident-to-Recovery Lifecycle
If you want to improve MTTR, first break it down to its components so that you can them identify the opportunities for improvement. Each stage involves delays and inefficiencies that are often overlooked in the overall MTTR metric. This includes:
- Detection: Detecting the occurrence of failure or abnormal condition on equipment
- Issue Diagnosis: Accurately knowing the cause and scope for the repair work to be done or what accurately to be included in a maintenance notification
- Planning & Approval of Work: Planning tasks, obtaining approvals and permit to work
- Resource Mobilization: Assembling technicians, tools, spares, consumables and all necessary SME support
- Actual Repair: Actual execution of maintenance tasks
- Testing & Stabilization: Verifying system integrity, restoring process steady state, and ensuring process compliance
- Ramp-Up & Handover: Returning equipment to normal operation, completing shift handovers, reporting hours and closing out documentation
Component analysis: Practical realities and typical delays
1. Detection
In manufacturing, any issue or abnormal condition detection relies on sensors, alarms, operator / technician shift routine rounds. Alarm floods, sensor failures, operator human errors may result in downtime incidents.
Typical Delays: Missed alarms during shift changes, sensor calibration issues, communication delays from field, notification process delays.
Failure Points: Alarm rationalization gaps, poor visibility in control rooms and to the people not sitting in control rooms, notification creation process delays.
2. Issue Diagnosis
Supervisors in maintenance or in production usually reviews the issues. They need to access to historical data, and often discuss with other departments like operations, quality, engineering hence cross-functional collaboration plays an important task. Complex assets like gas turbines, multistage gas compressors may require specialist input.
Typical Delays: Waiting for subject matter expertise, incomplete data, inaccessible manuals.
Failure Points: Shift handovers without proper context, siloed information, disconnected teams / subject matter expertise.
3. Planning & Approval of Work
Operational criticality, safety, compliance, and permit requirements dominate work planning. Many approvals are needed, especially for work at height, confined space or any hazardous tasks.
Typical Delays: Criticality assessment, risk assessment, permit backlog, slow management sign-off, WO creation process bottlenecks.
Failure Points: Paper based workflows (e.g. paper permits, risk assessments), no ready criticality visibility, access to accurate BOM, task lists.
4. Resource Mobilization
Mobilizing the right people, tools, consumables, spares and especially right PPE for the job. This is often hampered by inventory inaccuracies, dependency on OEMs, job scope clarity.
Typical Delays: Waiting for spares, SME arrival, or tool availability.
Failure Points: Inadequate spare parts tracking, OEM/SME response time.
5. Actual Repair
Repair work is constrained by readiness for work and hand over for maintenance by operations teams, safety protocols, access restrictions, and environmental conditions.
Typical Delays: Waiting for maintenance handover, safe entry, or permit clearance.
Failure Points: Miscommunication or timely and planning between cross functional teams, incomplete job scopes.
6. Testing & Stabilization
Post maintenance job testing must ensure compliance and operations team acceptance. Failures here can trigger repeated work.
Typical Delays: Waiting for QA inspections, process steady state, documentation completion.
Failure Points: Testing procedures not followed, Timely coordination with QA engineer, incomplete sign-off.
7. Ramp-Up & Handover
Final ramp-up and handover are often affected by shift changes, incomplete documentation.
Typical Delays: Waiting for incoming shift, closing out work orders and reporting hours, and updating logs.
Failure Points: Delayed and incomplete shift handovers, paper log books, delays in WO closure.
Digital Maturity for MTTR Improvements
Reducing MTTR requires targeted digital interventions based on current state maturity:
Digital (Data, Alarms, Workflows, Visibility):
- Sensor retrofitting / IOT and alarm rationalization improve incident detection.
- Digital mobile workforce to access engineering documents, standard maintenance procedures / work instructions, access to create notifications, WOs, maintenance history, risk assessments, on the fly SME connectivity etc.
- Integrated e- permit systems accelerate permit to work processes.
- Workflow automation for permit requests, shift handovers, shift logbooks, risk assessments, and approvals are routed efficiently.
- Automated spares requests (ROL, ROQ) and scheduling improve resource mobilization speed.
- Centralized remote monitoring centers, connected assets, integrity windows enable faster diagnosis by consolidating asset data.
- Condition based maintenance and advanced analytics for proactive maintenance
GenAI / Coordinated Agentic AI Agents:
- Generative AI produces incident summaries for quick notification, shift handover notes and maintenance procedures.
- AI driven copilot / knowledge bases provide instant access to manuals, SOPs, and past incident work / past learnings.
- Agents to monitor process data, detect anomalies, and recommend ‘next best actions’ actions in real time.
- Planning agentic assistants to auto classification & prioritization, to generate repair work package / WO including scopes, assign roles, resources etc.
- RCA Co-pilot to fast-track root cause analysis – fetches the past similar RCA, assembles the RCA report with best known information on the similar failure history
- Agents to initiate and track permit status.
- Resource agents to optimize mobilization by predicting spares needs and coordinating OEM responses.
Conclusion
Reducing MTTR (Mean Time To Repair) in manufacturing is not only about fixing things faster or relying only on technicians. It comes from cutting down the time taken to make decisions at every step from when a problem starts to when it is solved. Leaders need to understand that most delays happen because it takes time to detect issues, find the cause, get approvals, and gather resources, not just during the actual repair. MTTR should be handled as a complete system, and companies should invest in digital tools that reduce these delays, what is important is making quick decisions using real-time information, and ensuring everyone works together towards the factory’s main goals.